InnoDB存储引擎中的索引
0. 前言
在InnoDB存储引擎中,表都是根据主键顺序组织存放的,这种存储方式的表称为索引组织表(index organized table)。
在InnoDB存储引擎表中,每张表都有个主键(Primary Key),如果在创建表时没有显式地定义主键,则InnoDB存储引擎会按如下方式选择或创建主键:
- 首先判断表中是否有非空的唯一索引(Unique NOT NULL),如果有,则该列即为主键(如果有多个,则选取定义索引顺序的第一个,而不是定义列的顺序)
- 如果不符合上述条件,InnoDB存储引擎自动创建一个6字节大小的指针
1.InnoDB索引分类
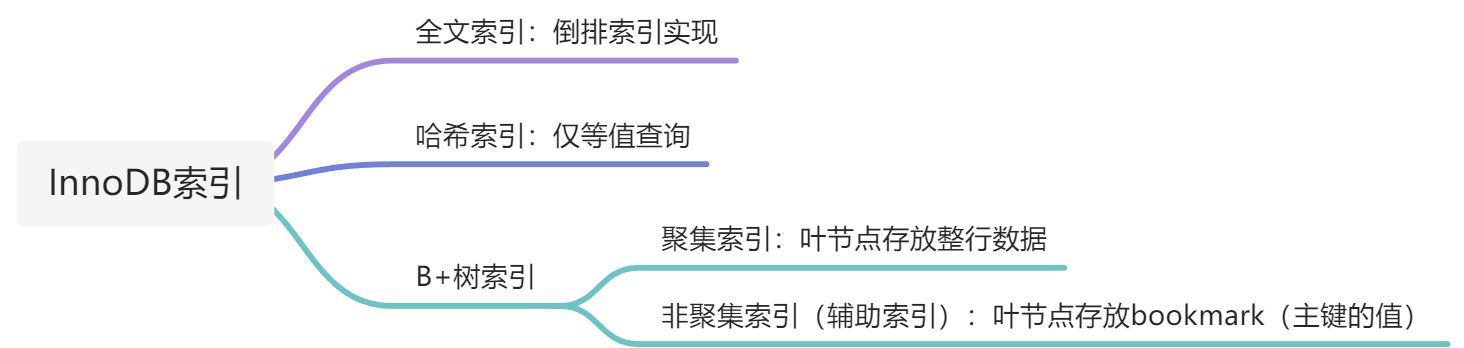
2.B+树索引
2.1聚集索引
聚集索引,又叫主键索引,按照每张表的主键构建一颗B+树,一个索引就是一颗B+树,叶子节点(数据页)存放整张表的行记录数据。
特点
- 聚集索引的存储并不是物理上连续,而是逻辑上连续
- 页通过双向链表链接,页按照主键的顺序排序
- 每个页中的记录也是通过双向链表进行维护的
- 由于实际的数据页只能按照一棵B+树进行排序,因此每张表只能拥有一个聚集索引。
- 在多数情况下,查询优化器倾向于采用聚集索引。因为聚集索引能够在B+树索引的叶子节点上直接找到数据
- 此外,由于定义了数据的逻辑顺序,聚集索引能够特别快地访问针对范围值的查询和排序。
2.2非聚集索引
辅助索引(Secondary Index,也称非聚集索引),叶子节点并不包含行记录的全部数据。叶子节点除了包含键值以外,每个叶子节点中的索引行中还包含了一个书签(bookmark)。该书签用来告诉InnoDB存储引擎哪里可以找到与索引相对应的行数据。由于InnoDB存储引擎表是索引组织表,因此InnoDB存储引擎的辅助索引的书签就是相应行数据的聚集索引键
特点
- 辅助索引的存在并不影响数据在聚集索引中的组织,因此每张表上可以有多个辅助索引
查找过程
查找一个非聚集索引,InnoDB引擎首先会遍历非聚集索引B+树,通过页级别的 指针找到指向聚集索引的键ID,然后通过这个ID键再去查找聚集索引,得到一个完整的行数据,这个过程叫做回表。
例子:
- 如果语句是 select * from T where ID=500,即主键查询方式,则只需要搜索 ID 这棵 B+ 树;
- 如果语句是 select * from T where k=5,即普通索引查询方式,则需要先搜索 k 索引树,得到 ID 的值为 500,再到 ID 索引树搜索一次
3.索引维护
在插入新纪录、删除旧纪录时,B+ 树为了维护索引有序性,会涉及到索引的维护问题。

- 如果 在上图中插入
ID=700的记录,则在R5后面插入一条新记录就行; - 如果插入
ID=400的记录,则需要移动R4,R5,然后把ID=400插进去;更糟糕的,如果R4所在的页满了,就需要申请新的页,挪动部分数据到新页上面(页分裂)
注意:
- 页分裂会降低空间利用率、性能
- 主键长度越小,普通索引的叶子节点就越小,普通索引占用的空间也就越小
4.索引应用
4.1联合索引
联合索引是指对表上的多个列进行索引
CREATE TABLE t(
a INT,
b INT,
PRIMARY KEY(a),
KEY idx_a_b(a,b)
)ENGINE=INNODB
显然,(a, b)的联合索引,也是按照(a, b)排序来存放的。
最左前缀匹配原则
联合索引中,如果你的 SQL 语句中用到了联合索引中的最左边的索引,那么这条 SQL 语句就可以利用这个联合索引去进行匹配。
这个最左前缀可以是:
- 联合索引的最左 N 个字段;
- 也可以是字符串索引的最左 M 个字符
例如:
- SELECT*FROM TABLE WHERE a=xxx and b=xxx,显可以使用(a,b)这个联合索引的
- SELECT*FROM TABLE WHERE a=xxx,也可以使用这个(a,b)索引
- SELECT*FROM TABLE WHERE b=xxx,则不可以使用这棵B+树索引
那么,如果非要查询b,怎么办?
如果安排联合索引顺序?
考虑索引字段的复用性。
- 如果通过调整顺序,可以少维护一个索引,那么这个顺序往往就是需要优先考虑采用的
- 考虑空间-性能权衡
为何要用联合索引?
- 减少不必要的索引开销:(a, b, c)这样一个联合索引,可以提供对(a, b, c),(a, b),(a)的索引查询
- 可以使用覆盖索引:
4.2覆盖索引
InnoDB存储引擎支持覆盖索引(covering index,或称索引覆盖),即从辅助索引中就可以得到查询的记录,而不需要查询聚集索引中的记录(不需要回表)。
执行流程
举个例子:
对于下图(name, age)联合索引,如下查询:
SELECT AGE FROM USER WHERE NAME='王五';执行流程:
- 在(name,age)联合索引树上找到名称为王五的节点
- 该节点里包含age信息,直接返回10
为何使用覆盖索引?
- 使用覆盖索引的一个好处是辅助索引不包含整行记录的所有信息,故其大小要远小于聚集索引,因此可以减少大量的IO操作,避免回表。
- 有利于某些统计操作,减少IO操作,例如count(*)
4.3索引下推
满足最左前缀原则的时候,最左前缀可以用于在索引中定位记录。这时,你可能要问,那些不符合最左前缀的部分,会怎么样呢?
举个例子:
 联合索引")
对于如下查询,只能根据最左前缀匹配“张”来定位到ID3,之后判断 age=10和 ismale=1是否满足。
select * from tuser where name like '张 %' and age=10 and ismale=1;- 在 MySQL 5.6 之前,只能从 ID3 开始一个个回表。到主键索引上找出数据行,再对比字段值。
- MySQL 5.6 引入的索引下推优化(index condition pushdown), 可以在索引遍历过程中,对索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数


InnoDB 在 (name,age) 索引内部就判断了 age 是否等于 10,对于不等于 10 的记录,直接判断并跳过。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!